프로젝트,실습/실습
파이썬 비즈니스 데이터 - rfm분석
mjmjpp
2024. 6. 10. 09:07
rfm분석
https://ko.wikipedia.org/wiki/RFM
RFM - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. RFM은 가치있는 고객을 추출해내어 이를 기준으로 고객을 분류할 수 있는 매우 간단하면서도 유용하게 사용될 수 있는 방법으로 알려져 있어 마케팅에서 가장
ko.wikipedia.org
- Recency - 거래의 최근성: 고객이 얼마나 최근에 구입했는가?
- Frequency - 거래빈도: 고객이 얼마나 빈번하게 우리 상품을 구입했나?
- Monetary - 거래규모: 고객이 구입했던 총 금액은 어느 정도인가?
rfm분석
1.유효데이터만 추출
2.이상치 제거
3.중복데이터 확인
4.중복데이터 제거
5.rfm계산
-> 전체주문에서 최근 주문일 구하기
->고객별 recency, frequency,monetary 값 구하기
6.rfm segment구하기
7.RFM score
0. 데이터 불러오기
import pandas as pd
df = pd.read_excel('C:/pmj/Online Retail.xlsx')
df
1. 유효데이터만 추출
#customerID가있고 Quantity,Unitprice가 0 보다 큰 데이터를 가져옴
#구매하고 취소한 건 중 취소한 건만 제외하고 구매건은 남김
df_copy=df[df['CustomerID'].notnull()&(df['Quantity']>0)&(df['UnitPrice']>0)].copy()df_copy
#r구매 금액계산
df_copy['TotalPrice']=df_copy['Quantity']*df_copy['UnitPrice']
df_copy#totalprice 의 기술통계값을 봅니다.
df_copy.describe()이상치 제거
# 범위를 설정하여 이상치를 찾습니다.
# 160000보다 큰 값을 찾습니다.
df_copy[df_copy['TotalPrice']>160000]
df_copy1=df_copy[df_copy['TotalPrice']<160000]중복데이터 확인
#중복 데이터 중 첫번째 것만 확인
#keep은 중복 데이터 발견 시에 어떤 데이터를 유지하고 제외할지 결정해주는 변수
df_copy1[df_copy1.duplicated()]# 중복된 행 찾기
duplicates = df_copy1.duplicated()
# 중복된 행의 개수 계산
num_duplicates = duplicates.sum()
print("Number of duplicate rows:", num_duplicates)
# 중복된 행 중 상위 2개 출력
print("Top 2 duplicate rows:")
print(df_copy1[duplicates].head(2))#중복데이터 모두 출력 (keep=false)하기
df_copy1[df_copy1.duplicated(keep=False)].sort_values(['InvoiceNo','StockCode'])중복데이터 제거
#drop_duplicates로 중복을 제거
df_copy12= df_copy1.drop_duplicates().copy()
df_copy12RFM계산
전체 주문에서 최근 주문일 구하기
#invoicedate를 날짜 형식으로 변환해주기
#데이트 타입으로 되어있을때 구하기 쉽기 때문
df_copy12['InvoiceDate']=pd.to_datetime(df_copy12['InvoiceDate'])
df_copy12['InvoiceDate'].head(1)0 2010-12-01 08:26:00
Name: InvoiceDate, dtype: datetime64[ns]import datetime as dt
#recency계산을 위해 해당 주문에서 가장 최근 구매가 일어난 시간을 가져옴
# 최근 거래 기준일(last_timestamp)을 만들기 위해 timedelta로 날짜를 더해줌(최솟값은 1을 설정)
last_timestamp=df_copy12['InvoiceDate'].max()+dt.timedelta(days=1)
last_timestampTimestamp('2011-12-10 12:50:00')고객별 recency, frequency,monetary 값 구하기
- Recency : 얼마나 최근에 구매했는가
-
- 최근 거래 기준일(life_timestamp)과 고객별 최근 구매한 날짜 (x.max())와 차이값
- Frequency : 얼마나 자주 구매했는가
-
- 구매 빈도수
- Monetary : 얼마나 많은 금액을 지출했는가
-
- 구매 금액
#고객 아이디별로 최근에 구매한 일수가 뜸
rfm=df_copy12.groupby('CustomerID').agg({'InvoiceDate': lambda x :(last_timestamp - x.max()).days,
'InvoiceNo':'count',
'TotalPrice':'sum'})#rfm으로 변수의 이름을 변경하기
#invoicedata는 recency
#invoiceno는 frequency
#totalprice는 momentaryvalue
rfm=rfm.rename(columns={'InvoiceDate':'Regency',
'InvoiceNo':'Frequency',
'TotalPrice':'Momentaryvalue'})
rfm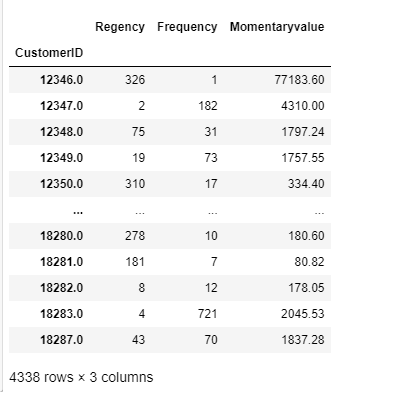
rfm.describe()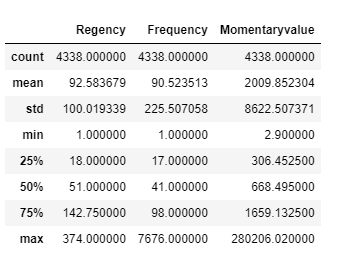
rfm.hist(bins=50);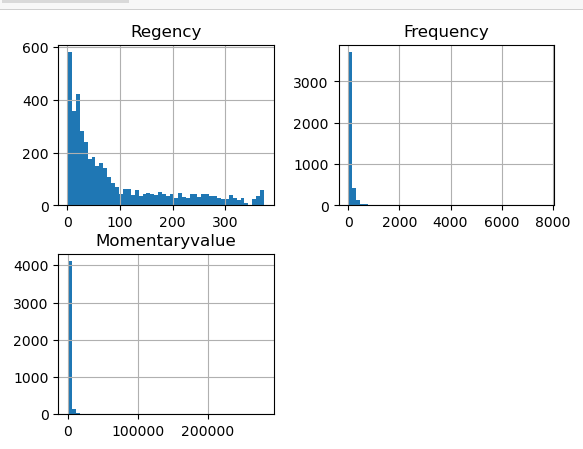
# qcut으로 비슷한 비율씩 원하는 등급의 갯수만큼 나눠보자.
#Regency는 최근일 수록 높은 스코어를 갖도록 함
#Frequency,Momentaryvalue 는 값이 클수록 높은 스코어를 갖도록 함
r_labels=list(range(5,0,-1))
f_labels=list(range(1,6))
m_labels=list(range(1,6))
cut_size=5r_qcnt=pd.qcut(x=rfm['Regency'],q=cut_size,labels=r_labels)
r_qcnt.value_counts(1)
f_qcnt=pd.qcut(x=rfm['Frequency'],q=cut_size,labels=f_labels)
m_qcnt=pd.qcut(x=rfm['Momentaryvalue'],q=cut_size,labels=m_labels)r_qcnt.value_counts(1)
f_qcnt.value_counts(1)
m_qcnt.value_counts(1)1 0.200092
3 0.200092
5 0.200092
2 0.199862
4 0.199862
Name: Momentaryvalue, dtype: float64#assign을 활용하면 여러변수를 한번에 만들 수 잇음
rfm=rfm.assign(R=r_qcnt,F=f_qcnt,M=m_qcnt)
rfm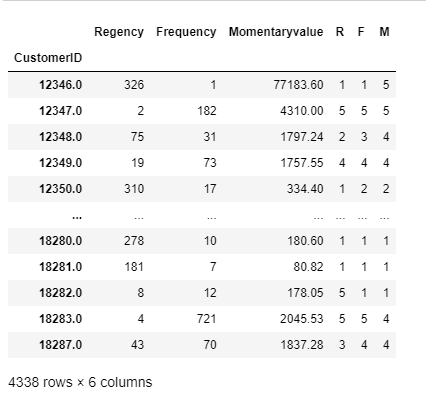
rfm segment구하기
#rfm_segment 값을 구하기
#r,f,m값을 문자 그대로 붙여서 세그멘트를 구분한다.
rfm['RFM_Segment']=rfm['R'].astype(str)+rfm['F'].astype(str)+rfm['M'].astype(str)
rfm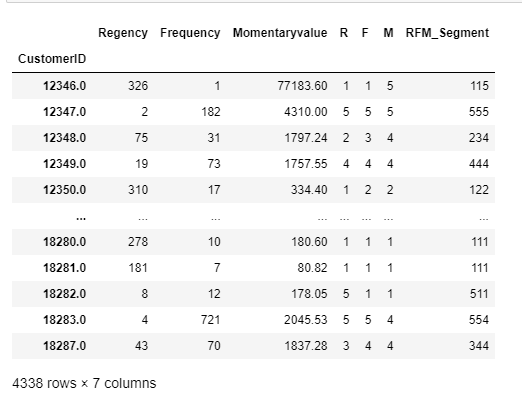
RFM score
#R,F,M 값의 합계를 구해서 세그먼트 점수를 구함
# rfm['RFM_score']
rfm['RFM_score']=rfm[['R','F','M']].astype(int).sum(axis=1)
rfm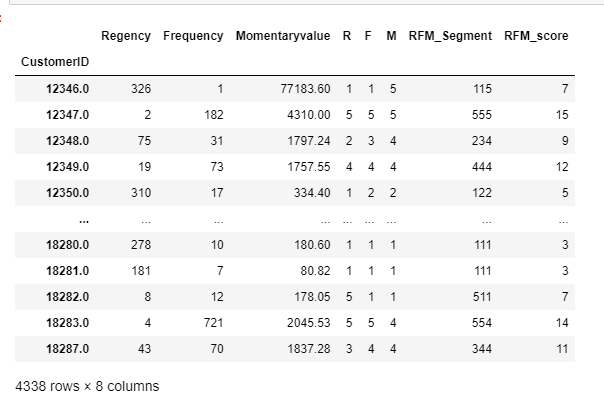
#RFM segment값에 따라 정렬합니다.
plt.figure(figsize=(20,4))
plt.xticks(rotation=90)
sns.barplot(data=rfm.sort_values('RFM_Segment'),x='RFM_Segment',y='RFM_score')
#3차원그래프에 표현
ax=plt.axes(projection='3d')
ax.scatter3D(rfm['R'],rfm['F'],rfm['M'])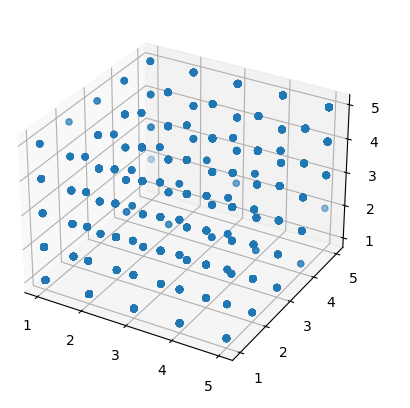
#3차원그래프에 표현(원래의 값)
ax=plt.axes(projection='3d')
ax.scatter3D(rfm['Regency'],rfm['Frequency'],rfm['Momentaryvalue'])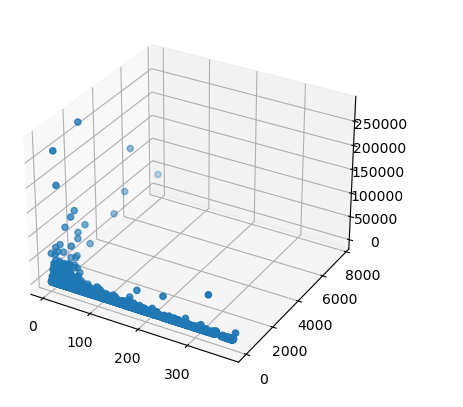
rfm.hist();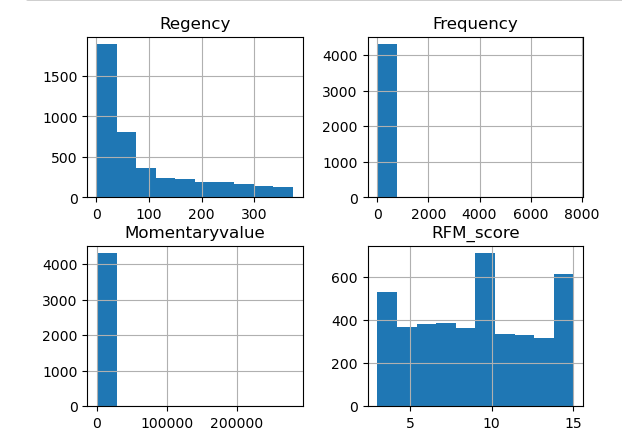
rfm.astype(int).hist(bins=5,figsize=(10,6))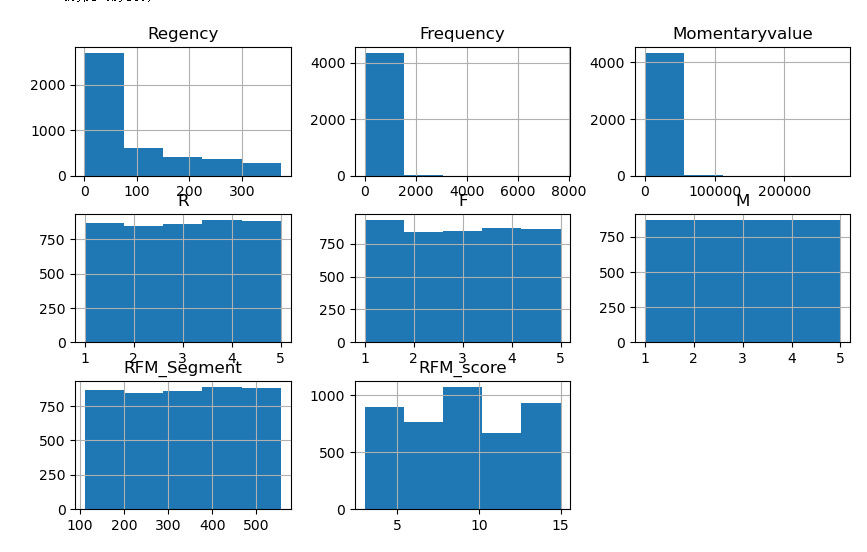
#문자열의 format 함수를 사용하여 소수점 아래는 표기하지 않도록 문자열 포맷을 지정
rfm.groupby('RFM_score').agg({'Regency':'mean','Frequency':'mean','Momentaryvalue':['mean','sum']}).style.background_gradient().format("{:,.0f}")
#해석-> rfm_score 가 15점으로 만점이다.== 평균적으로 구매한지 5일 이내다.
#fm_score 가 15점으로 만점이다.== 평균적으로 439회 주문했다.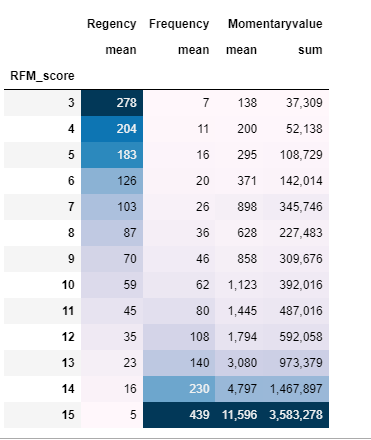
#qcnt를 통해 3단계로 'silver','gold','platinum'고객군으로 나눈다.
rfm['RFM_class']=pd.qcut(x=rfm['RFM_score'],q=3,labels=['silver','gold','platinum'])
rfm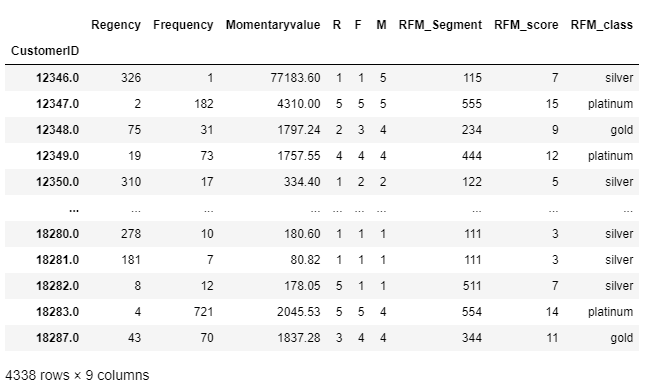
#RFM_class별로 그룹화하고 RFM_score의 describe값을 구함
rfm.groupby('RFM_class')['RFM_score'].describe()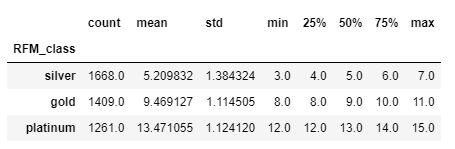
#barplot으로 rfm_score별 평균 rfm_score나타냄
sns.barplot(data=rfm,x='RFM_class',y='RFM_score')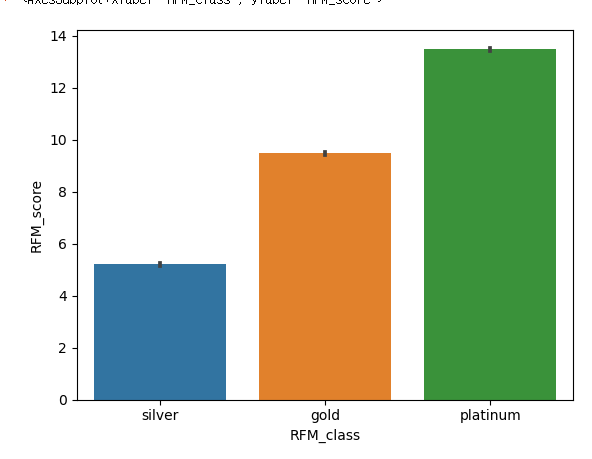
#boxplot으로 RFM_class별 평균 RFM_ score 나타냄
sns.boxplot(data=rfm, x='RFM_class',y='RFM_score')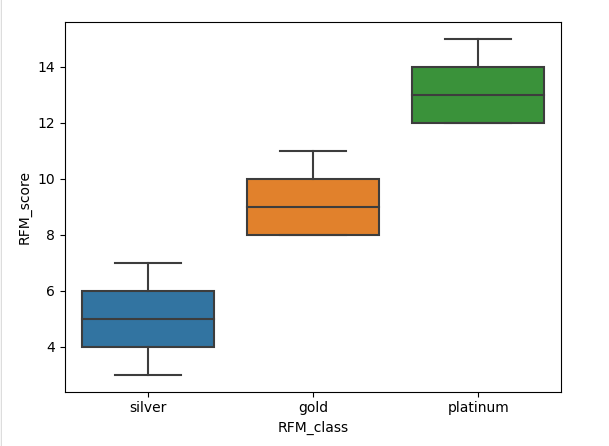
#pointplot으로 x=R,hue=RFM_class별 평균 y=RFM_score나타냅니다.
#hue 옵션을 사용하면 특정 컬럼을 지정해서 표기할 수 있습니다.
sns.pointplot(data=rfm,x='R',y='RFM_score',hue='RFM_class')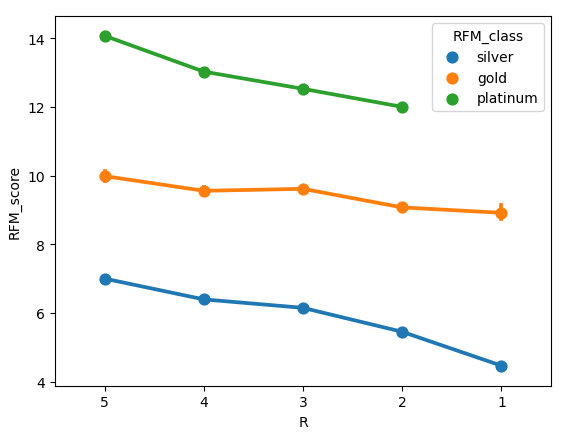
sns.pointplot(data=rfm,x='F',y='RFM_score',hue='RFM_class')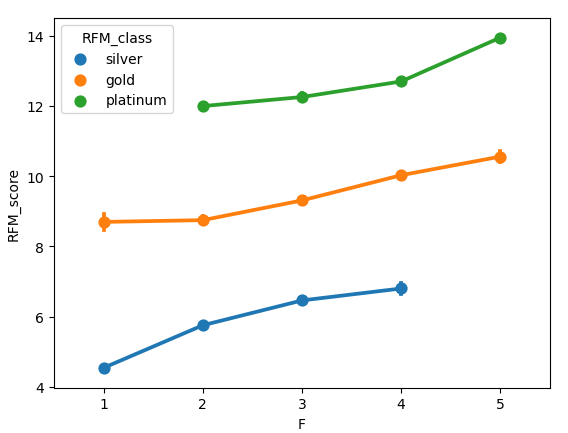
sns.pointplot(data=rfm,x='M',y='RFM_score',hue='RFM_class')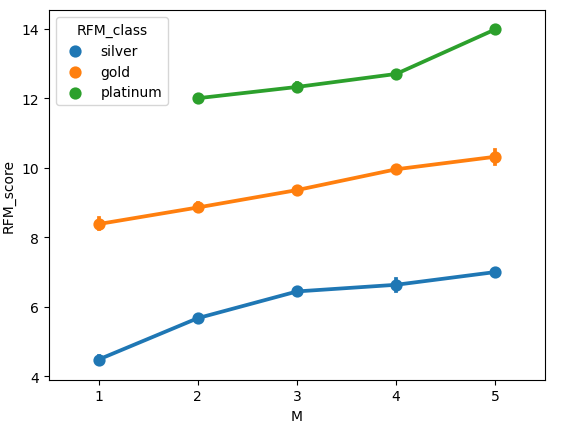
#RFM_CLASS별로 그룹화함
#'Recency','Frequency'의 평균을 구합니다.
# 'Monetaryvalue'의 'mean','sum','count'값을 구합니다.
rfm.groupby('RFM_class').agg({'Regency':'mean','Frequency':'mean','Momentaryvalue':['mean','sum','count']})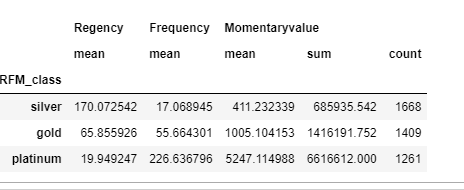
위에서 구한 값을 시각화
rfm.groupby('RFM_class').agg({'Regency':'mean','Frequency':'mean','Momentaryvalue':['mean','sum','count']}).style.background_gradient().format("{:,.0f}")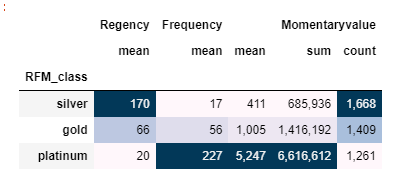
#pairplot을 통해 'rfm_class'별로 분포를 시각화 합니다.
sns.pairplot(data=rfm.sample(300),hue='RFM_class')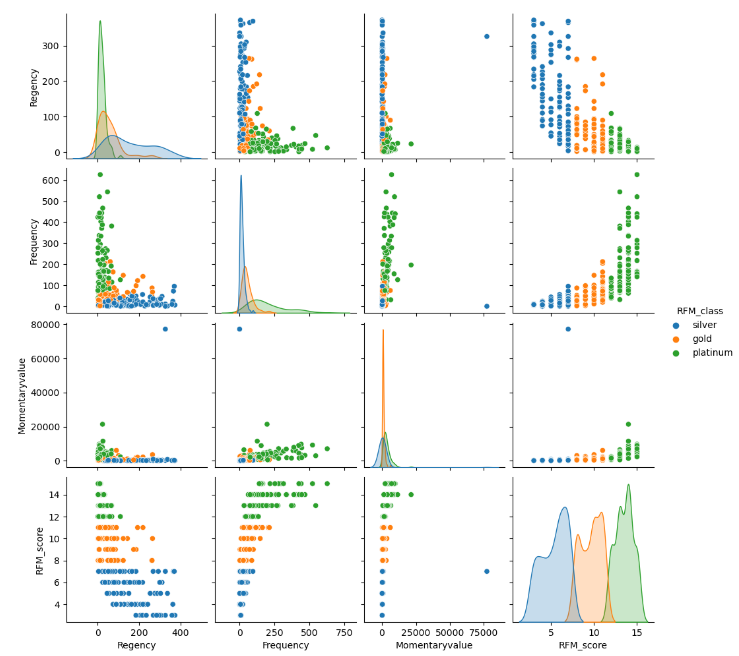
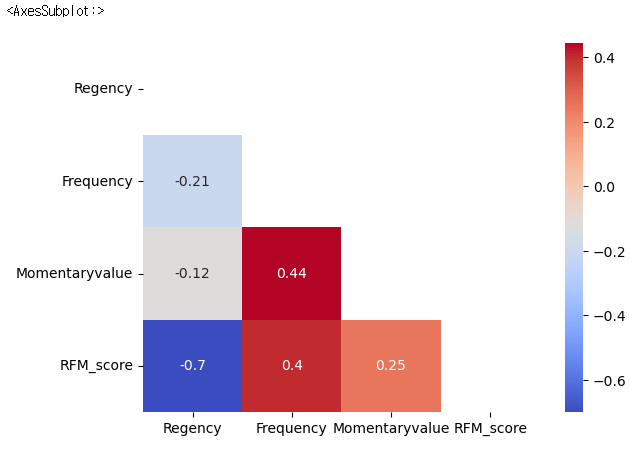
#.corr()함수로 변수간 상관관계(선형적 관계)를 분석합니다.
#1에 가까울 수록 양의 상관관게, -1에 가까울 수록 음의 상관관계를 나타냄
corr=rfm.select_dtypes(include='number').corr()
corr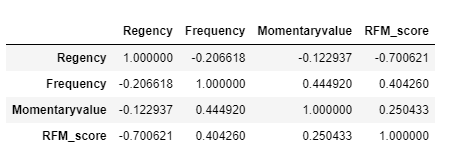
#삼각 형태의 heatmap 형태를 만들기 위해 삼깍형 마스크를 만듭니다.
import numpy as np
mask=np.triu(np.ones_like(corr))
#상관관계를 열분포 형태의 이미지로 보여주는 heatmap으로 데이터를 시각화함
sns.heatmap(corr,annot=True,cmap='coolwarm',mask=mask)