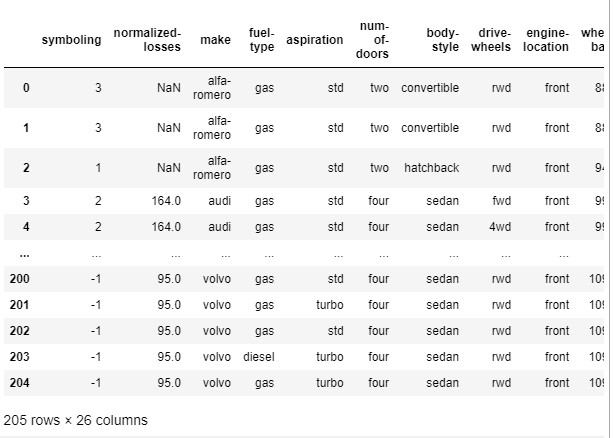
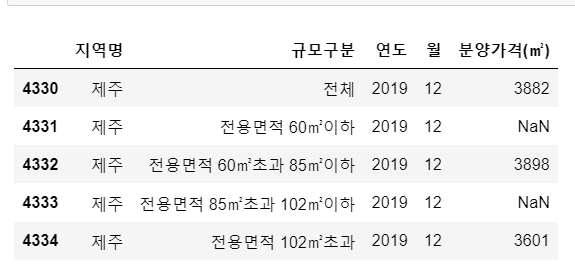
1.사이킷런으로 시작하는 머신러닝 1) 학습/테스트 데이터 셋 분리 * 교차검증을 통해 교차 검증을 통해 모델의 일반화 성능을 평가하고 과적합을 판단 -> k-fold교차 검증, stratified k-fold, cross_val_score() 2) 최적의 파라미터 값찾기 gridsearchcv(), 여기서 cv=5이교 이거는 5개의폴드로 나눈다는 것임 3)데이터 인코딩 : labelencoder(),onehotencoder() 4)피처 스케일링과 정규화 : standardscaler()-표준화, minmaxscaler()-정규화 -> 규모가 다른 피처들의 영향을 동등하게 만듦 -> 모든 피처의 값의 범위를 비슷하게 만들어주면, 모델이 각 피처의 영향을 동등하게 고려 *총정리 머신러닝 애플리케이션 (데이..